
Semantic and Geometric Reasoning for Robotic Grasping: A Probabilistic Logic Approach
Laura Antanas, Plinio Moreno, Marion Neumann, Rui Pimentel de Figueiredo,
Kristian Kersting, José Santos-Victor, Luc De Raedt
I hereby again recall that this work is not mine, but the one of:
Laura Antanas, Plinio Moreno, Marion Neumann, Rui Pimentel de Figueiredo, Kristian Kersting, José Santos-Victor, and Luc De Raedt.
I simply try to make a complete summary, that is easier to quickly read than the original paper. Thanks for the authors for contributing to science in such an incredible manner!
Abstract :
- A probabilistic logic approach for robot grasping, which improves grasping capabilities by leveraging semantic object parts
- robot is provided with semantic reasoning skills given the task constraints and object properties, while also dealing with the uncertainty of visual perception and grasp planning.
- Task-dependant logic framework, reasoning about pre-grasp configurations w.r.t the intended task
- employs object-task affordances and object/task ontologies to encode rules that generalize over similar object parts and object/task categories
- current approaches: learn direct mappings from visual perceptions to task-dependent grasping
points
VS this approach: uses probabilistic logic for task-dependent grasping - The framework is able to perform robotic grasping in realistic kitchen-related scenarios
The framework architecture on a cup point cloud example:

I. Introduction
The tackled problem here: how to take into account specific manipulation scenario properties (e.g. object, its functionalities and properties, gripper configuration, …).
Contribution: Probabilistic logic module that semantically reason about the most likely object part to be grasped, given the object properties and task constraints.
Benefits of the approach:
- generalization over similar (multiple) object parts
- reduction of the grasping inference space by reasoning about possible task-constrained grasps
- enhancement of object category estimation by employing both semantic part labels and object shape and curvature information
The authors refer to Gibsonian’s definition of affordance, concentrating on possible actions of an object.
They try to tackle the research question:
Does semantic high level reasoning help to select a better grasp if the next task is known?
Goal: use the PLM to help the grasp planner by reducing the space of possible final gripper poses
Logic offers a natural way to integrate high-level world knowledge such as:
- subsumption relations among object categories (encoded by an object ontology),
- task categories (encoded by the task ontology), and
- relations between object categories and tasks (encoded by object-task affordances), in a compact rule-based grasping model.
Because descriptions of the perceived world are uncertain (e.g., not all cups look like the ‘prototypical’ cup), we consider probabilistic logic which allows reasoning about the uncertainty in the world.
The main features of the PLM include:
- a general rule-based model integrating task information and object category for robotic grasping
- a semantic part-based representation of the objects that generalizes across several categories and allows reasoning by means of logic
- a new probabilistic logic approach to object grasping which uses high-level knowledge such as object-task affordances and object/task ontologies to generalize over object/task categories and improve robot grasping
II. Proposed framework

Visual perception module:
After segmenting the object point cloud and performing a full object shape reconstruction, the visual module estimates object properties such as pose, symbolic parts and geometric-based object category.

PLM for taskdependent grasping:
Given the input observations, it is able to reason about the grasping scenario. It can (re)predict and improve the category of the object via the semantic object categorization model. Further, the module can answer queries
about the most likely task and most likely object part to grasp, given the task (denoted as pre-grasp).It uses probabilistic visual observations about the object provided by the first module, evidence about the task and world knowledge such as object/task ontologies and object-task affordances.
Low-level Grasp Planner:
Once we have identified the most likely pre-grasp, the framework calls the third module, which solves the problem of planning the grasp execution by using local shape features of the object part and completing it on the robotic platform

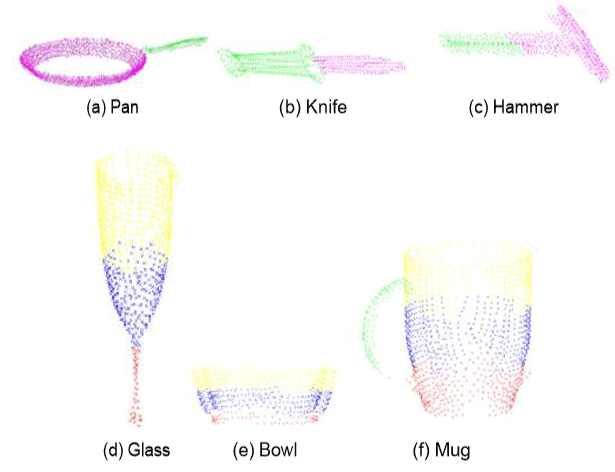
The vision module detects symbolic parts top, middle, bottom and handle.
Global object similarity helps to complete the scene description with a prior on object category (cup = 0.56, can=0.35 and pan=0.05). The PLM gives a new distribution (cup=0.98 and pan=0.02), due to the handle.
Object task affordance and world knowledge have the PLM predicting the tasks pass, pick-place, and pick-place inside upright with the same probability.
For
III. Related Work
This section review state-of-the-art of (i) visual grasping, (ii) task-dependant grasping and (iii) statistical relational learning for robotics.
1 Visual-dependant grasping
Most grasping methods consider mainly visual features to learn a mapping from 2D/3D features to grasping parameters. A major shortcoming is: it is difficult to link a 3D gripper orientation to solely local image features.
Recently, approaches considering global information have been proposed, that increase geometric robustness.
However, for global information, we need the complete shape of the object. We need shape completion, that is complicated to get when single view available (time efficient, …).
An interesting method, from Thrun and Wegbreit, takes advantage of symmetries (5 basic and 3 composite types of them). Partly based on this work, Kroemer et al. propose an extrusion based approach able to deal with shapes not handled by symmetry-based approaches (but not yet suitable in real-time).
Other approaches use prior such as the table-top assumption, or decompose the CAD model into geometric primitives and define rules for them.
Here we implemented an efficient shape completion approach which translates a set of environmental assumptions into a set of approximations, allowing us to reconstruct the object point cloud in real-time, given a partial view of the object.
2 Task-dependant grasping
Task-dependant grasping is mostly done by learning a direct mapping function between good grasps and geometrical and action constraints, action features and object attributes. A part of this work focuses on Bayesian network learning to integrate symbolic task goals and low-level continuous features such as object attributes, action properties and constraint features.
The discrete part-based representation allows robust grasping.
Several approaches make use of object affordances for grasping. Two presented papers present estimated visual-based latent affordances and grasp selection by modeling affordance relations between objects, actions and effects using either a fully probabilistic setting or a rule-based ontology.
We here exploit additional object/task ontologies using probabilistic reasoning and leverage low-level learning and semantic reasoning. This allows us to experiment with a wide range of object categories.
3 Statistical Relational Learning for robot grasping and other robotic tasks
Probabilistic relational robotics is an emerging area within robotics that aims at endowing robots with a new level of robustness in real-world situations. Probabilistic relational models have been used to integrate common-sense knowledge about the structure of the world to successfully accomplish search tasks in an efficient and reliable goal-directed manner.
Abstract knowledge representation and symbolic knowledge processing for formulating control decisions as inference tasks have proven powerful in autonomous robot control. These decisions are sent as queries to a knowledge base. SRL techniques using Markov Logic Networks and Bayesian Logic Networks are investigated in two cited papers.
In probabilistic planning, relational rules have been exploited for efficient and flexible decision-theoretic planning and probabilistic inference has proven successful for integrating motor control, planning, grasping and high-level reasoning.
Symbolic reasoning enables the robot to solve tasks that are more complex than the individual, demonstrated actions.
These approaches successfully intertwine relational reasoning and learning in robotics. However, none of these frameworks solves the generalization capability needed for task-dependent grasping following a semantic and affordance-based behavior.
We propose a probabilistic logic framework to infer pre-grasp configurations using task-category affordances. Our approach features semantic generalization and can tackle unknown objects. This research topic has great importance in robotics as robots aimed at working in daily environments should be able to manipulate many never-seen-before objects and to deal with increasingly complex scenarios.
IV. Semantic Vision-based Scene Description
The visual module is used to obtain a semantic description of the perceived objects in terms of their pose, symbolic parts and probability distributions over possible object categories.
An ideal model, considering object semantics, shape, affordances, motion planning and the task being performed on it, should consider both discrete and continuous variable, while dealing with uncertainty.
As in small households spaces (as kitchen), space is limited, the work is here driven by the motion planning constraints. As a result:
- Robot needs large power equipment, reducing significantly the task workspace
- Holistic view of the object is not possible, depending on the context: if lying on a table, or in a shelf, or in a drawer
- Our main assumption is that we can estimate the bounding box of every semantic part from a partial view of the object. To accomplish this, we assume that all the objects are symmetric (partially or globally).
- Discrete object poses. We consider poses upright, upside-down, and sideways.
- Low-level grasp planning is customized to the particular end-effector and it is learned independently of the task, using only point cloud statistics in the selected part. Here the robot has a two-finger-gripper. This allows easy switching of the end-effector as only the grasp planning model should be learned again, and not the rest (semantic and geometric reasoning part)
- The grasping control and stability is here not addressed. We use a Schunk WSG.
In practice, in a kitchen scenario we consider the categories pan, cup, glass, bottle, can, knife, and in a workshop scenario we consider the categories hammer and screwdriver.
The object symmetry assumption allows us to apply shape completion algorithms. Then, using the shape-completed point cloud, we segment the object into its parts and assign them a semantic label (in top, middle, bottom, handle and usable area). This reduces the search space for robot grasp generation, prediction and planning.
1 Object shape completion
Computing the bounding box of an object is an ill posed problem due to lack of observability of the self-occluded part. However, the actual bounding shape provides a large set of reaching poses (i.e. pre-grasp hypotheses), which lead to successful grasping.
We propose an approach that translates a set of assumptions and rules of thumb observed in many daily environments into a set of heuristics and approximations:
- the objects stand on top of a planar surface
- the camera is at a higher viewpoint
- the objects have rotational symmetry
- their main geometrical axes are either orthogonal or parallel to the supporting plane
- the axis of symmetry corresponds to one of the main geometrical axes
- the direction of the axis of symmetry indicates the object’s pose
These constraints model perfectly simple box-like and cylinder-like object shapes, such as kitchen-ware tools, and are reasonable assumptions for many other approximately symmetric objects, such as tools. The heuristics allow us to reconstruct the unobserved part of an object point cloud in real-time, given a partial view.
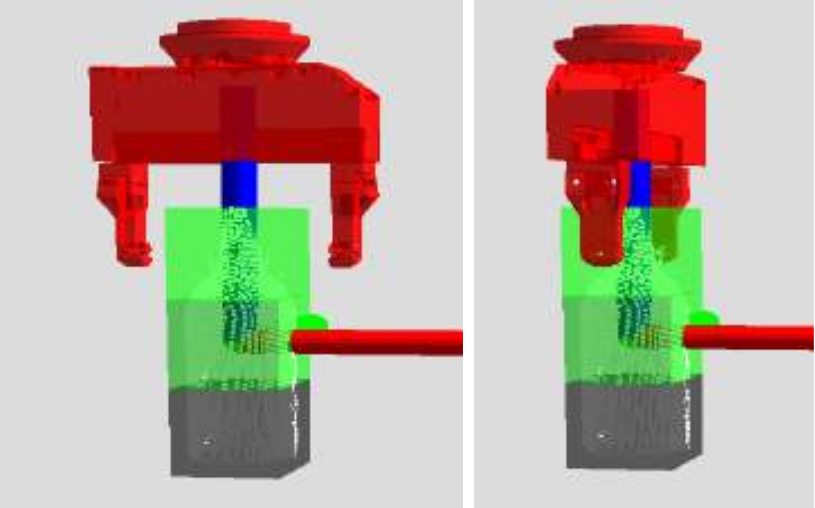
The next figure illustrate cases where these asumption apply:

Thanks to these assumptions, they are able to reconstruct the unobserved part of an object point cloud in real-time, given a partial view, as the ones on this figure:
They use PCA to find the main geometrical axis. Then to identify the parts of the object:
- If the direction is perpendicular to the table, the object may have or not a handle.
They say: “The object has a handle if the projection of the points onto the table plane fits very likely a circle.”I guess they mean you have to get a circle plus some other line from this projection.
Then the symmetry completion is applied to the potential handle and to the rest (or full object if no handle).
- If the direction is parallel to the table (i.e. the object is lying on the table), they look at the height. If it’s too small, the object is a tool, and they use linear symmetry to find the handle and the usable area.
Otherwise, it is not, and they apply the same as in 1.
They use line reflection symmetry, that better copes with the object categories they consider, they use bounding boxes to define pre-grasp hypotheses: two hypotheses by face, as illustrated hereafter:
The set of pre-grasp poses is used by the low-level grasp planner for local-shape grasping prediction and motion trajectory planning.
They provide their software implementation and the ROS node for object pose and part segmentation here.
2 Object properties
From the completed point cloud and its semantic parts, they estimate its pose, category and containment.
- Object pose: The orientation of the axis of symmetry with respect to the object’s supporting plane indicates the pose of the object (upright, upside-down or sideways). In our real-world experiments we do not estimate the upside-down pose.
(The pose is here simplified, as categorized in only 3 positions), a continuous representation could be more accurate, but more costly also. I would have take the robotic arm/end effector as reference frame, not the table.
- Similarity-based object classification: We can estimate the object class by retrieving the objects with the most similar global properties. Due to good results for grasping point prediction, we employ the manifold-based graph kernel approach proposed in another paper to asses global object similarity. The prediction, in the form of a probability distribution on object labels, is used further as a prior by the probabilistic logic module. Other global object similarity methods can be also used instead.
“We obtain the distribution on object categories for a particular object by retrieving the objects in an object database being most similar in terms of global shape and semantic part information. We represent the objects by labeled graphs, where the labels are the semantic part labels derived by the visual module and the graph structure given by a k-nearest neighbor (k-nn) graph of the completed object’s point cloud. For each completed object we derive a weighted k-nn graph by connecting the k nearest points w.r.t. Euclidean distance in 3D.”
The nodes have five semantic labels encoding object part information top, middle, bottom, handle and usable area. The similarity measure among objects is a kernel function over counts of similar node label distributions, per diffusion iteration. We consider a maximum number of iterations.
Given a new object G^* that the robot aims to grasp, we first select the top n most similar graphs {G(1),..., G(n)}, where n = 10 in all our experiments.
The prior for the scenario in this next figure is:
P = 0.56 (cup), P = 0.36 (can), P = 0.05 (pot), and P = 0.02 (pan).
It is used by the PLM to reason about different prediction tasks.
I guess using neural networks on a 2D image should be something more efficient for categorisation.
Object containment: In our scene description we additionally consider observations about the object containment. It can be estimated by comparing top visual images of empty and full objects (opened containers) or by observing human (or humanoid) lifting and transportation actions (closed containers). We assume either that the containment property is not observed (e.g., for tools), the object is empty, or the object is full, with a certain probability.
This is for me something to work on, a tool should not have a containment property “not observed”.
V. CP-Logic for Task-dependent Grasping
To be continued…