
Intrinsically Motivated grasping (IROS WS published)
[KGVID]http://quentindelfosse.me/wp-content/uploads/2019/09/Thor-Video-1080.mp4[/KGVID]
The robot is very slow because was used a lot to calibrate, and in this first version, the motors were heating a lot.
Another version of the robot with cooling systems and with more heat-resistant parts is currently being built.
Another post detailing how were built the two robotic arms and what other projects are planed with them can be found here.
The paper: Open-Ended Learning of Grasp Strategies using
Intrinsically Motivated Self-Supervision
I hereby want to thank the people who allowed me to do this research:
Pr. Jan Peters, director of the lab, whose advice was really helpful to quickly get on track, Vieri Santucci, author of the paper on which we rely for this work, and Svenja Stark and Daniel Tanneberg, whose help all along this path into intrinsically motivated reinforcement learning and grasping was really appreciated.
This post is not strictly scientific, but also meant for people not from this field to understand.
Here is a link to the scientific paper.
Abstract
Despite its apparent ease, grasping is one major unsolved task of robotics. Equipping robots with dexterous manipulation skills is a crucial step towards autonomous and assistive robotics.
This paper presents a task space controlled robotic architecture for open-ended self-supervised learning of grasp strategies, using two types of intrinsic motivation signals.
By using the robot-independent concept of object offsets, we are able to learn grasp strategies in a simulated environment, and to directly transfer the knowledge to a different 3D printed robot.
I Introduction
This work aims to create a lifelong grasping learning robot.
Our approach, using what we call offset in task/cartesian space, allows us to easily transfer knowledge between robots/grippers, as the learned part is specific to the objects.
II Approach
A. The base architecture: GRAIL
We here rely on the work of Vieri Santucci et al.: GRAIL, the Goal-Discovering Robotic Architecture for Intrinsically-Motivated Learning that allows a robot from a virtual environment to discover abstract goals, create internal representations of those, and use Competence-Based Intrinsic Motivation to self-supervise its learning.
In GRAIL, the agent is equipped with goals slots and experts. The core idea is to have the robot self determining on which goal to train and what expert to use in order to be the more efficient in terms of performance improvement (this is using Competence Based Intrinsic Motivations, more detail in this blog post).
The agent randomly selects one of its goal slot, then randomly selects one expert to complete this goal. The expert makes the robot move. If the robot triggers one goal (here corresponding to touching a sphere that floats in the air), the architecture detects it, and links the goal with the current goal slot, and reinforce the goal and expert (i.e. augment the probability of their selection).
Thus, the robots is able to detect goals and form a nice discrete intern representation of them.
To select the goals and expert to train on meaningfully, all goals are rated, and the selection is made through a softmax on their grade. The same process is applied to experts. Every expert is rated for each goal.
The softmax allows stochasticity, and thus exploration. Every time a goal and a corresponding expert are selected, their grades are updated following an Exponential Moving Average rule:
G^t = (1 - \alpha)G^{t-1} + \alpha (p^t - p^{t-1})
with G^t the grade at time t, p^t the observed performance (thus p^t - p^{t-1} being the performance improvement), and \alpha a smoothing factor.
B. Extending the Architecture
Several extensions are provided through this work. I detail them hereafter.
1. Infinite number of instanciable goals and experts.
One of the problem of the initial architecture for lifelong learning is that it is equipped with a predefined number of goals slots and experts, that are then randomly attributed for solving a task.
We have created instanciable goals and experts. This approach supposes to have another way of discovering goals in the environment, which was anyway necessary for our grasping task. Indeed, we consider here the shapes of our objects as goals. These shapes’ categorization is not really discoverable by a robot in the same manner (i.e. by randomly exploring) and is more a computer vision problem.
Here is a scheme of our new architecture:

2. Application to grasping: using the offset notion
A lot of current approaches for learning to grasp goes try to directly learn a mapping from the image to the joint space. These approaches try to take advantage of the huge power of deep reinforcement learning. These approaches should theoretically work well, but they suffer from several drawbacks:
- They are very sample expensive and robots samples are not cheap to produce. One can use virtual environments for this but would then have to deal with the sim-to-real problem. This problem is notably addressed by google in a mixed approach, where they train both in virtual environment and on real robots.
- When not converging, the network is pretty much a black box, where it’s difficult to dive in (Explainable Machine Learning might help here).
- The model will implicitly have to relearn parts that are already mathematically solved (such as Inverse Kinematics, potentially with collision detection…)
The biggest point here is that we try to learn several aptitudes by having the experts competing in solving different goals. This method takes advantage of several initializations, that might drastically help and boost convergence, but we are not able to have several huge networks compete (convergence would take years). Furthermore, our experts are supposed to each solve one particular goal, whereas the approached based on Deep Reinforcement Learning tend to be general.
We thus decided to divide the grasping task into several sub-tasks that we solve independantly:
- Finding the object type (i.e. shape), and its size ~ Computer Vision
- Finding the object pose (i.e. position and orientation) ~ Computer Vision
- Sending the end effector to the object ~ Inverse Kinematics
- Moving the end effector around the object for an optimal grasp ~ Offset Learning
This last point is what our network learns: the offset. It corresponds to this small shift that is shape, pose and size dependent of the object, and of the end-effector. It is illustrated through the pictures bellow:


The first image correspond to the robot send to the object from the top (high chances of grasping if no prior knowledge on the object shape and pose is given), without the add of any offset. The end effector is sent to the center of the object, that is here not respondable (hence the end effector going through it).
The second image represent an add of the offset to the initial object pose. The robot has shift from the center and rotate to perform a successful grasp (i.e. the object will be lifted).
3. Adding transfer learning
Something else that we have implemented is transfer learning. Indeed, this would help to take advantage of this competition between experts. The idea of transfer learning is twofold:
- when a new goal is discovered, good performing experts of already existing goals should be tried on this new one. Most of the objects in the world are apprehended by human similarly (cans, bottles, glasses, … etc can be grasped from their “side”), and this can bootstrap learning
- transfer learning can also be done on existing experts to boost learning even between existing goals, or have them discovering new pre-grasping poses (i.e. if learning to grasp from the top is done on a cylinder but not on the cube, transfer and adjustment of the specific expert knowledge would create a new expert with this capacity).
Our experts can thus be copied between goal, a new expert should then be fine-tuned.
4. Using another Competence Based Intrinsic Motivation to bootstrap
GRAIL uses Maximizing competence progress motivation (described in this post) to self organize the learning order of the goals and chose the expert to learn on (goals and experts making the most progress have higher chances to be selected).
One problem is one does not have access to the progress of the expert after initializing them, but only to the performance. For this reason, no initial grade is accessible. GRAIL’s authors solve this problem by giving the same grade to each expert. This could be problematic for several reasons. According to the grade that one gives (and the smoothing factor and the temperature in the softmax), one implicitly selects the probability of a goal to be selected at least once in the n first episode.
For example: We grade the performance between 0 and 1. If all grades are 0, with a very high temperature and a high smoothing factor, then a performance improvement of 0.01 would give a very high probability to this goal to be reselected in the next episode.
One might argue that this is a way to balance exploration/exploitation, but it has then to be adjusted by the designer. We decided to thus use the initial performance as the initial grade. Then the first goals and experts to get selected are likely to be the ones that show a very good potential to end up with very good performances, as they are already the best performing ones.
The agent should thus initially prioritize the goals on which he is performing good, then the ones on which he makes most improvement. The combination of these two types of intrinsic motivations have our agent behave even more in a human-like way to self-supervize its learning.
III EXPERIMENTS AND RESULTS
Our setup is simulated in V-REP and consists of a Kuka LBR R820 manipulator and a table on which objects are placed (as shown on the previous figures).
During learning, the robot encounters objects of certain shapes, which differ in their size and pose. The next figure describes the self-supervised learning procedure of one run. The upper part shows the experts performances (only the selected experts are represented) and the lower part show the normalized goal score, before using the softmax.
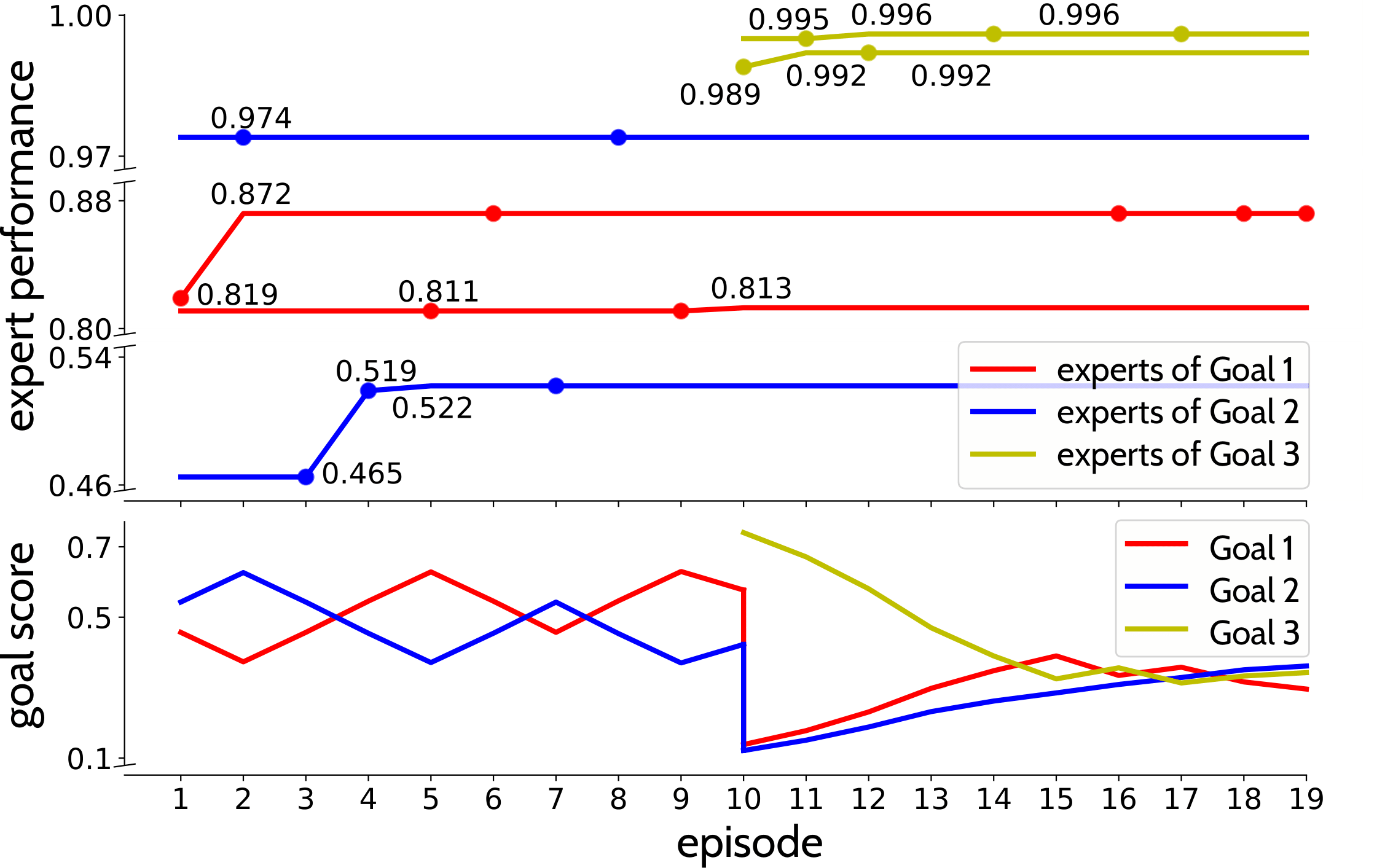
One episode corresponds to the selected expert performing stochastic hill climbing to improve its performance with 10 trials. For each goal, experts with high grades are first selected (stochastically), and if no (further) progress is made, their selection probability decreases, as the performance improvement is low. Hence, the worse performing cylinder expert (Goal 2) is selected after the better one fails to improve.
Grasps are considered successful when the object is lifted without slipping, i.e., a stable grasp achieves maximum performance.
After Episode 10, we place a new object in the environment and the architecture autonomously discovers it. Four new experts are instantiated for the new goal, but only two are selected during training (see the figure above).
After few training iterations on this new goal, performances and progress are similar to the other goals, and the architecture automatically trains on all of them.
Working with offsets in task space allows an easy transfer of the learned grasp strategies.
We show this by transferring the strategies learned on the Kuka arm in simulation to an open source 3D printed robot, Thor.
The robot has performed successful grasps for several object positions despite its different kinematics and shape (please look at the video on the top of this page to see one successful grasp).
IV CONCLUSION AND DISCUSSION
To enable real open-ended learning, we extended GRAIL’s self-supervised learning to handle infinitely many goals and experts and to transfer knowledge between experts.
Further, it is possible to transfer strategies from one robot to another, which we show by training on a simulated robot manipulator and a successful transfer to a different 3D printed robot.
We are currently training the architecture on a wider range of goals, and we are planning to integrate an object decomposition framework to learn grasping of more complex objects.